



ChatGPT
Best engine so far
A new series of GPT models featuring major improvements on coding, instruction following, and long context—plus our first-ever nano model. 可通过API调用
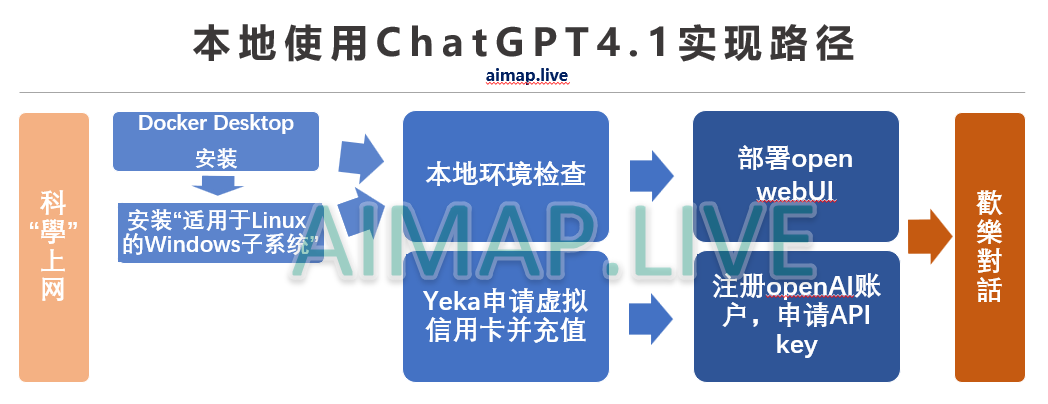
使用方法请见文章 首发!ChatGPT4.1本地使用全指南 – 小白+普通电脑也能用
ChatGPT4.1详细介绍 Introduction
Today, we’re launching three new models in the API: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano. These models outperform GPT‑4o and GPT‑4o mini across the board, with major gains in coding and instruction following. They also have larger context windows—supporting up to 1 million tokens of context—and are able to better use that context with improved long-context comprehension. They feature a refreshed knowledge cutoff of June 2024.
GPT‑4.1 excels at the following industry standard measures:
While benchmarks provide valuable insights, we trained these models with a focus on real-world utility. Close collaboration and partnership with the developer community enabled us to optimize these models for the tasks that matter most to their applications.
To this end, the GPT‑4.1 model family offers exceptional performance at a lower cost. These models push performance forward at every point on the latency curve.

GPT‑4.1 mini is a significant leap in small model performance, even beating GPT‑4o in many benchmarks. It matches or exceeds GPT‑4o in intelligence evals while reducing latency by nearly half and reducing cost by 83%.
For tasks that demand low latency, GPT‑4.1 nano is our fastest and cheapest model available. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding—even higher than GPT‑4o mini. It’s ideal for tasks like classification or autocompletion.
These improvements in instruction following reliability and long context comprehension also make the GPT‑4.1 models considerably more effective at powering agents, or systems that can independently accomplish tasks on behalf of users. When combined with primitives like the Responses API(opens in a new window), developers can now build agents that are more useful and reliable at real-world software engineering, extracting insights from large documents, resolving customer requests with minimal hand-holding, and other complex tasks.
Note that GPT‑4.1 will only be available via the API. In ChatGPT, many of the improvements in instruction following, coding, and intelligence have been gradually incorporated into the latest version(opens in a new window) of GPT‑4o, and we will continue to incorporate more with future releases.
We will also begin deprecating GPT‑4.5 Preview in the API, as GPT‑4.1 offers improved or similar performance on many key capabilities at much lower cost and latency. GPT‑4.5 Preview will be turned off in three months, on July 14, 2025, to allow time for developers to transition. GPT‑4.5 was introduced as a research preview to explore and experiment with a large, compute-intensive model, and we’ve learned a lot from developer feedback. We’ll continue to carry forward the creativity, writing quality, humor, and nuance you told us you appreciate in GPT‑4.5 into future API models.
Below, we break down how GPT‑4.1 performs across several benchmarks, along with examples from alpha testers like Windsurf, Qodo, Hex, Blue J, Thomson Reuters, and Carlyle that showcase how it performs in production on domain-specific tasks.
GPT‑4.1 is significantly better than GPT‑4o at a variety of coding tasks, including agentically solving coding tasks, frontend coding, making fewer extraneous edits, following diff formats reliably, ensuring consistent tool usage, and more.
On SWE-bench Verified, a measure of real-world software engineering skills, GPT‑4.1 completes 54.6% of tasks, compared to 33.2% for GPT‑4o (2024-11-20). This reflects improvements in model ability to explore a code repository, finish a task, and produce code that both runs and passes tests.
For API developers looking to edit large files, GPT‑4.1 is much more reliable at code diffs across a range of formats. GPT‑4.1 more than doubles GPT‑4o’s score on Aider’s polyglot diff benchmark(opens in a new window), and even beats GPT‑4.5 by 8%abs.This evaluation is both a measure of coding capabilities across various programming languages and a measure of model ability to produce changes in whole and diff formats. We’ve specifically trained GPT‑4.1 to follow diff formats more reliably, which allows developers to save both cost and latency by only having the model output changed lines, rather than rewriting an entire file. For best code diff performance, please refer to our prompting guide(opens in a new window). For developers who prefer rewriting entire files, we’ve increased output token limits for GPT‑4.1 to 32,768 tokens (up from 16,384 tokens for GPT‑4o). We also recommend using Predicted Outputs(opens in a new window) to reduce latency of full file rewrites.
GPT‑4.1 also substantially improves upon GPT‑4o in frontend coding, and is capable of creating web apps that are more functional and aesthetically pleasing. In our head-to-head comparisons, paid human graders preferred GPT‑4.1’s websites over GPT‑4o’s 80% of the time.
GPT‑4o
GPT‑4.1
Beyond the benchmarks above, GPT‑4.1 is better at following formats more reliably and makes extraneous edits less frequently. In our internal evals, extraneous edits on code dropped from 9% with GPT‑4o to 2% with GPT‑4.1.
Windsurf(opens in a new window): GPT‑4.1 scores 60% higher than GPT‑4o on Windsurf’s internal coding benchmark, which correlates strongly with how often code changes are accepted on the first review. Their users noted that it was 30% more efficient in tool calling and about 50% less likely to repeat unnecessary edits or read code in overly narrow, incremental steps. These improvements translate into faster iteration and smoother workflows for engineering teams.
Qodo(opens in a new window): Qodo tested GPT‑4.1 head-to-head against other leading models on generating high-quality code reviews from GitHub pull requests using a methodology inspired by their fine-tuning benchmark. Across 200 meaningful real-world pull requests with the same prompts and conditions, they found that GPT‑4.1 produced the better suggestion in 55% of cases(opens in a new window). Notably, they found that GPT‑4.1 excels at both precision (knowing when not to make suggestions) and comprehensiveness (providing thorough analysis when warranted), while maintaining focus on truly critical issues.
GPT‑4.1 follows instructions more reliably, and we’ve measured significant improvements across a variety of instruction following evals.
We developed an internal eval for instruction following to track model performance across a number of dimensions and in several key categories of instruction following, including:
These categories are the result of feedback from developers regarding which facets of instruction following are most relevant and important to them. Within each category, we’ve split up easy, medium, and hard prompts. GPT‑4.1 improves significantly over GPT‑4o on hard prompts in particular.
Multi-turn instruction following is critical for many developers—it’s important for the model to maintain coherence deep into a conversation, and keep track of what the user told it earlier. We’ve trained GPT‑4.1 to be better able to pick out information from past messages in the conversation, allowing for more natural conversations. The MultiChallenge benchmark from Scale is a useful measure of this capability, and GPT‑4.1 performs 10.5%abs better than GPT‑4o.
GPT‑4.1 also scores 87.4% on IFEval, compared to 81.0% for GPT‑4o. IFEval uses prompts with verifiable instructions (for example, specifying content length or avoiding certain terms or formats).
Better instruction following makes existing applications more reliable, and enables new applications previously limited by poor reliability. Early testers noted that GPT‑4.1 can be more literal, so we recommend being explicit and specific in prompts. For more on prompting best practices for GPT‑4.1, please refer to the prompting guide.
Blue J(opens in a new window): GPT‑4.1 was 53% more accurate than GPT‑4o on an internal benchmark of Blue J’s most challenging real-world tax scenarios. This jump in accuracy—key to both system performance and user satisfaction—highlights GPT‑4.1’s improved comprehension of complex regulations and its ability to follow nuanced instructions over long contexts. For Blue J users, that means faster, more reliable tax research and more time for high-value advisory work.
Hex(opens in a new window): GPT‑4.1 delivered a nearly 2× improvement on Hex’s most challenging SQL evaluation set,(opens in a new window) showcasing significant gains in instruction following and semantic understanding. The model was more reliable in selecting the correct tables from large, ambiguous schemas—an upstream decision point that directly impacts overall accuracy and is difficult to tune through prompting alone. For Hex, this resulted in a measurable reduction in manual debugging and a faster path to production-grade workflows.
GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano can process up to 1 million tokens of context—up from 128,000 for previous GPT‑4o models. 1 million tokens is more than 8 copies of the entire React codebase, so long context is a great fit for processing large codebases, or lots of long documents.
We trained GPT‑4.1 to reliably attend to information across the full 1 million context length. We’ve also trained it to be far more reliable than GPT‑4o at noticing relevant text, and ignoring distractors across long and short context lengths. Long-context understanding is a critical capability for applications across legal, coding, customer support, and many other domains.
Below, we demonstrate GPT‑4.1’s ability to retrieve a small hidden piece of information (a “needle”) positioned at various points within the context window. GPT‑4.1 consistently retrieves the needle accurately at all positions and all context lengths, all the way up to 1 million tokens. It is effectively able to pull out relevant details for the task at hand regardless of their position in the input.

In our internal needle in a haystack eval, GPT‑4.1, GPT‑4.1 mini, and GPT 4.1 nano are all able to retrieve the needle at all positions in the context up to 1M.
However, few real-world tasks are as straightforward as retrieving a single, obvious needle answer. We find users often need our models to retrieve and understand multiple pieces of information, and to understand those pieces in relation to each other. To showcase this capability, we’re open-sourcing a new eval: OpenAI-MRCR (Multi-Round Coreference).
OpenAI-MRCR tests the model’s ability to find and disambiguate between multiple needles well hidden in context. The evaluation consists of multi-turn synthetic conversations between a user and assistant where the user asks for a piece of writing about a topic, for example “write a poem about tapirs” or “write a blog post about rocks”. We then insert two, four, or eight identical requests throughout the context. The model must then retrieve the response corresponding to a specific instance (e.g., “give me the third poem about tapirs”).
The challenge arises from the similarity between these requests and the rest of the context—models can easily be misled by subtle differences, such as a short story about tapirs rather than a poem, or a poem about frogs instead of tapirs. We find that GPT‑4.1 outperforms GPT‑4o at context lengths up to 128K tokens and maintains strong performance even up to 1 million tokens.
But the task remains hard—even for advanced reasoning models. We’re sharing the eval dataset(opens in a new window) to encourage further work on real-world long-context retrieval.

In OpenAI-MRCR(opens in a new window), the model must answer a question that involves disambiguating between 2, 4, or 8 user prompts scattered amongst distractors.
We’re also releasing Graphwalks(opens in a new window), a dataset for evaluating multi-hop long-context reasoning. Many developer use cases for long context require multiple logical hops within the context, like jumping between multiple files when writing code or cross referencing documents when answering complicated legal questions.
A model (or even a human) could theoretically solve an OpenAI-MRCR problem by doing one pass or read-through of the prompt, but Graphwalks is designed to require reasoning across multiple positions in the context and cannot be solved sequentially.
Graphwalks fills the context window with a directed graph composed of hexadecimal hashes, and then asks the model to perform a breadth-first search (BFS) starting from a random node in the graph. We then ask it to return all nodes at a certain depth. GPT‑4.1 achieves 61.7% accuracy on this benchmark, matching the performance of o1 and beating GPT‑4o handily.
Benchmarks don’t tell the full story, so we worked with alpha partners to test the performance of GPT‑4.1 on their real-world long context tasks.
Thomson Reuters:(opens in a new window) Thomson Reuters tested GPT‑4.1 with CoCounsel, their professional grade AI assistant for legal work. Compared to GPT‑4o, they were able to improve multi-document review accuracy by 17% when using GPT‑4.1 across internal long-context benchmarks—an essential measure of CoCounsel’s ability to handle complex legal workflows involving multiple, lengthy documents. In particular, they found the model to be highly reliable at maintaining context across sources and accurately identifying nuanced relationships between documents, such as conflicting clauses or additional supplementary context—tasks critical to legal analysis and decision-making.
Carlyle(opens in a new window): Carlyle used GPT‑4.1 to accurately extract granular financial data across multiple, lengthy documents—including PDFs, Excel files, and other complex formats. Based on their internal evaluations, it performed 50% better on retrieval from very large documents with dense data and was the first model to successfully overcome key limitations seen with other available models, including needle-in-the-haystack retrieval, lost-in-the-middle errors, and multi-hop reasoning across documents.
In addition to model performance and accuracy, developers also need models that respond quickly to keep up with and meet users’ needs. We’ve improved our inference stack to reduce the time to first token, and with prompt caching, you can cut latency even further while saving on costs. In our initial testing, latency to first token for GPT‑4.1 was approximately fifteen seconds with 128,000 tokens of context, and a minute for a million tokens of context. GPT‑4.1 mini and nano are faster, e.g., GPT‑4.1 nano most often returns the first token in less than five seconds for queries with 128,000 input tokens.
The GPT‑4.1 family is exceptionally strong at image understanding, with GPT‑4.1 mini in particular representing a significant leap forward, often beating GPT‑4o on image benchmarks.
Long context performance is also important for multimodal use cases, such as processing long videos. In Video-MME(opens in a new window) (long w/o subs), a model answers multiple choice questions based on 30-60 minute long videos with no subtitles. GPT‑4.1 achieves state-of-the-art performance, scoring 72.0%, up from 65.3% for GPT‑4o.
GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano are available now to all developers.
Through efficiency improvements to our inference systems, we’ve been able to offer lower prices on the GPT‑4.1 series.GPT‑4.1 is 26% less expensive than GPT‑4o for median queries, and GPT‑4.1 nano is our cheapest and fastest model ever. For queries that repeatedly pass the same context, we are increasing the prompt caching discount to 75% (up from 50% previously) for these new models. Finally, we offer long context requests at no additional cost beyond the standard per-token costs.
| Model (Prices are per 1M tokens) | Input | Cached input | Output | Blended Pricing* |
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
*Based on typical input/output and cache ratios.
These models are available for use in our Batch API(opens in a new window) at an additional 50% pricing discount.
GPT‑4.1 is a significant step forward in the practical application of AI. By focusing closely on real-world developer needs—ranging from coding to instruction-following and long context understanding—these models unlock new possibilities for building intelligent systems and sophisticated agentic applications. We’re continually inspired by the developer community’s creativity, and are excited to see what you build with GPT‑4.1.
A full list of results across academic, coding, instruction following, long context, vision, and function calling evals can be found below.
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| AIME ’24 | 48.1% | 49.6% | 29.4% | 13.1% | 8.6% | 74.3% | 87.3% | 36.7% |
| GPQA Diamond1 | 66.3% | 65.0% | 50.3% | 46.0% | 40.2% | 75.7% | 77.2% | 69.5% |
| MMLU | 90.2% | 87.5% | 80.1% | 85.7% | 82.0% | 91.8% | 86.9% | 90.8% |
| Multilingual MMLU | 87.3% | 78.5% | 66.9% | 81.4% | 70.5% | 87.7% | 80.7% | 85.1% |
[1] Our implementation of GPQA uses a model to extract the answer instead of regex. For GPT-4.1, the difference was <1% (not statistically significant), but for GPT-4o model extraction improves scores significantly (~46% -> 54%).
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified2 | 54.6% | 23.6% | – | 33.2% | 8.7% | 41.0% | 49.3% | 38.0% |
| SWE-Lancer | $176K (35.1%) | $165K (33.0%) | $77K (15.3%) | $163K (32.6%) | $116K (23.1%) | $160K (32.1%) | $90K (18.0%) | $186K (37.3%) |
| SWE-Lancer (IC-Diamond subset) | $34K (14.4%) | $31K (13.1%) | $9K (3.7%) | $29K (12.4%) | $11K (4.8%) | $29K (9.7%) | $17K (7.4%) | $41K (17.4%) |
| Aider’s polyglot: whole | 51.6% | 34.7% | 9.8% | 30.7% | 3.6% | 64.6% | 66.7% | – |
| Aider’s polyglot: diff | 52.9% | 31.6% | 6.2% | 18.2% | 2.7% | 61.7% | 60.4% | 44.9% |
[2] We omit 23/500 problems that could not run on our infrastructure. The full list of 23 tasks omitted are ‘astropy__astropy-7606’, ‘astropy__astropy-8707’, ‘astropy__astropy-8872’, ‘django__django-10097’, ‘django__django-7530’, ‘matplotlib__matplotlib-20488’, ‘matplotlib__matplotlib-20676’, ‘matplotlib__matplotlib-20826’, ‘matplotlib__matplotlib-23299’, ‘matplotlib__matplotlib-24970’, ‘matplotlib__matplotlib-25479’, ‘matplotlib__matplotlib-26342’, ‘psf__requests-6028’, ‘pylint-dev__pylint-6528’, ‘pylint-dev__pylint-7080’, ‘pylint-dev__pylint-7277’, ‘pytest-dev__pytest-5262’, ‘pytest-dev__pytest-7521’, ‘scikit-learn__scikit-learn-12973’, ‘sphinx-doc__sphinx-10466’, ‘sphinx-doc__sphinx-7462’, ‘sphinx-doc__sphinx-8265’, and ‘sphinx-doc__sphinx-9367’.
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| Internal API instruction following (hard) | 49.1% | 45.1% | 31.6% | 29.2% | 27.2% | 51.3% | 50.0% | 54.0% |
| MultiChallenge | 38.3% | 35.8% | 15.0% | 27.8% | 20.3% | 44.9% | 39.9% | 43.8% |
| MultiChallenge (o3-mini grader)3 | 46.2% | 42.2% | 31.1% | 39.9% | 25.6% | 52.9% | 50.2% | 50.1% |
| COLLIE | 65.8% | 54.6% | 42.5% | 50.2% | 52.7% | 95.3% | 98.7% | 72.3% |
| IFEval | 87.4% | 84.1% | 74.5% | 81.0% | 78.4% | 92.2% | 93.9% | 88.2% |
| Multi-IF | 70.8% | 67.0% | 57.2% | 60.9% | 57.9% | 77.9% | 79.5% | 70.8% |
[3] Note: we find that the default grader in MultiChallenge (GPT-4o) frequently mis-scores model responses. We find that swapping the grader to a reasoning model, like o3-mini, improves accuracy on grading significantly on samples we’ve inspected. For consistency reasons with the leaderboard, we’re publishing both sets of results..Note: we find that the default grader in MultiChallenge (GPT-4o) frequently mis-scores model responses. We find that swapping the grader to a reasoning model, like o3-mini, improves accuracy on grading significantly on samples we’ve inspected. For consistency reasons with the leaderboard, we’re publishing both sets of results.
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| OpenAI-MRCR: 2 needle128k | 57.2% | 47.2% | 36.6% | 31.9% | 24.5% | 22.1% | 18.7% | 38.5% |
| OpenAI-MRCR: 2 needle 1M | 46.3% | 33.3% | 12.0% | – | – | – | – | – |
| Graphwalks bfs <128k | 61.7% | 61.7% | 25.0% | 41.7% | 29.0% | 62.0% | 51.0% | 72.3% |
| Graphwalks bfs >128k | 19.0% | 15.0% | 2.9% | – | – | – | – | – |
| Graphwalks parents <128k | 58.0% | 60.5% | 9.4% | 35.4% | 12.6% | 50.9% | 58.3% | 72.6% |
| Graphwalks parents >128k | 25.0% | 11.0% | 5.6% | – | – | – | – | – |
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| MMMU | 74.8% | 72.7% | 55.4% | 68.7% | 56.3% | 77.6% | – | 75.2% |
| MathVista | 72.2% | 73.1% | 56.2% | 61.4% | 56.5% | 71.8% | – | 72.3% |
| CharXiv-R | 56.7% | 56.8% | 40.5% | 52.7% | 36.8% | 55.1% | – | 55.4% |
| CharXiv-D | 87.9% | 88.4% | 73.9% | 85.3% | 76.6% | 88.9% | – | 90.0% |
| Category | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o(2024-11-20) | GPT-4o mini | OpenAI o1(high) | OpenAI o3-mini(high) | GPT-4.5 |
|---|---|---|---|---|---|---|---|---|
| ComplexFuncBench | 65.5% | 49.3% | 0.6% | 66.5% | 38.6% | 47.6% | 17.6% | 63.0% |
| Taubench airline4 | 49.4% | 36.0% | 14.0% | 42.8% | 22.0% | 50.0% | 32.4% | 50.0% |
| Taubench retail4, 5 | 68.0% (73.6%) | 55.8% (65.4%) | 22.6% (23.5%) | 60.3% | 44.0% | 70.8% | 57.6% | 68.4% |
[4] tau-bench eval numbers are averaged across 5 runs to reduce variance, and run without any custom tools or prompting.
[5] Numbers in parentheses represent Tau-bench results when using GPT-4.1 as the user model, rather than GPT-4o. We’ve found that, since GPT-4.1 is better at instruction following, it is better able to perform as the user, and so results in more successful trajectories. We believe this represents the true performance of the evaluated model on the benchmark.

